
There’s a lot of information out there about A/B testing and how to figure out if one marketing method or configuration is more effective than your current approach.
When conversion experts, statisticians, and entrepreneurs talk about statistical difference and making sure these tests are actually significant, they usually talk about Type I errors. A Type I error is when your change makes no real statistical difference, but you think there is one. These usually happen because your sample size is too small…or because you’re not great at math.
Anyway, it’s important to prevent these errors because you could end up spending a lot of time and effort chasing things that don’t really affect your marketing efforts.
But you’re actually way more likely to screw something up when you don’t mean to. For example, if we change some things on the back end of our sign up process or make a design change, we want to make sure the change doesn’t negatively affect sign ups.
Basically, we want to make sure we don’t get a false negative (we think something won’t make things worse, but it actually will). This is the same thing as a doctor testing to see if someone has strep throat, and getting a negative result, when the patient actually does have strep. This is called a Type II error.
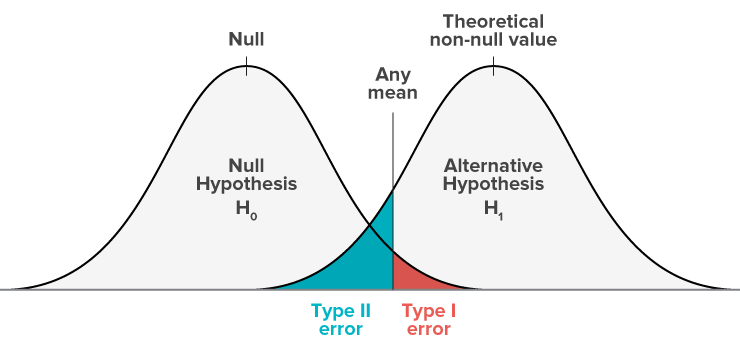
So why is this important? Well, when it comes to statistical significance most split test tools and discussions focus on Type I errors. This can be misleading when you are trying to verify that a change has not made things worse. Specifically if your change shows an even or slightly negative result, the actual result could be worse than you think due to Type II error.
Running Tests to Figure Out if Something is Worse
A lot of the time, you’ll test to see if something is better than what you had before, but here are three instances where you’d need to make sure something isn’t worse:
-
Updating your website to be more modern. After a few years, many businesses want to update their websites to fit into a modern aesthetic. It’s important to make sure that a new design won’t scare customers away.
-
Switching a backend system. You might change something in your database to help your engineers, but will this change affect the experience for customers in any way? You need to make sure that this change doesn’t make anything worse!
-
**Changing steps of a process.**For example, you might change your sign up from a one page process to a 3 page process in order to get more information from customers.
In these instances, you'll need to be careful your changes don't make things worse when they get deployed.
Determining Sample Size to Get Results
In order to get statistically significant results, you’ll need to figure out your sample size, but the numbers are different when calculating an increase versus a decrease in conversion.
Here’s the table I turn to when figuring out sample size. It uses a one-tailed 99% significance level for both an increase and decrease.
| Conversion Change | Sample for Increase | Sample for Decrease | |-------------------|---------------------|---------------------| | 25% | 65,000 | 110,000 | | 20% | 100,000 | 175,000 | | 15% | 180,000 | 320,000 | | 10% | 380,000 | 740,000 | | 5% | 1,500,000 | 3,000,000 | | 1% | N/A | 77,000,000 |
As you can see, I need 100,000 visitors to get statistically significant results when I’m calculating an increase assuming a difference of 20%, but I need 175,000 when calculating a decrease. Why is this? Well, I am concerned with Type I error when calculating significance for an increase and I am concerned with Type II error when calculating significance for a decrease.
You will also notice that in both cases you need more visitors to discern a smaller difference. This is important. Before starting your test you need to decide how much of a change you require to conclude that the change you made had an effect (either positive or negative). This means that you will discard changes that have an effect that is less than the threshold. In essence by selecting the 15% level you are saying that you will discard any change that moves conversion by less than this amount (positive or negative).
So, in addition to needing more visitors to ensure you don’t see a false negative from Type II error, you may need to set your change threshold at a lower value because you may not be willing to accept a 10% decrease in conversion.
But let’s be honest—most small businesses don’t get this many visitors.
Making Sure You Don’t Get a Type II Error
At Grasshopper, we changed the back end of our sign up process, switching from Java to Angular. This wasn’t a change our visitors would even see, but I needed to know that this change wasn’t going to negatively impact our conversion rates. In other words, I needed to make sure our conversion rate would remain the same.
It was important to make sure that things wouldn’t be worse. I needed more confidence than when I’m testing to see if things are better.
When the Test is Inconclusive
If you select a 15% threshold, run your test, and then get anything less than 15% difference, you really can’t tell if you’re doing better or worse.
When you are testing to verify that your change has not harmed conversion you now have a choice – do I make the change permanent? or do I discard the change and leave my site as-is?
Often, the people in your organization 'want' to make the change, making this a hard decision. Plus, because of the large amount of time required to truly get statistically significant results with a tight threshold, you’ll be left to do some manual calculations. It just isn’t practical for most sites to get 750,000 or a million visitors in one split test.
As I mentioned before, this problem is exasperated when the new result is the same as the control or slightly lower than the control.
I have found that the best thing to do in this situation is to subtract the new result from the control, calculate the standard deviation of the combined distribution and then see how much of the resulting distribution is greater than zero. This will give you the percent chance that your new result is not worse than the old result.
This isn't pure from a statistical perspective, but we've found that it works really well when working with these types of test.
Top Takeaways for Entrepreneurs Running Tests
It’s tempting to believe every test you run, but you’ve got to be careful. You need to make sure you’re calculating results so that they’re statistically significant, resulting in results that are free of both Type I and Type II errors.
How should you do this? Well, start by acknowledging that you need a pretty significant sample size to get the results you want, and make sure you’re running the test long enough to get actual results.
Now, get testing.

